SPIRE Concepts
An overview of SPIRE’s architecture and fundamentals
SPIRE is a production-ready implementation of the SPIFFE APIs that performs node and workload attestation in order to securely issue SVIDs to workloads, and verify the SVIDs of other workloads, based on a predefined set of conditions.
This section describes the architecture and components of SPIRE, walks you through “a day in the life of” how SPIRE issues an identity to a workload, and looks at some basic SPIRE concepts.
SPIRE Architecture and Components
A SPIRE deployment is composed of a SPIRE Server and one or more SPIRE Agents. A server acts as a signing authority for identities issued to a set of workloads via agents. It also maintains a registry of workload identities and the conditions that must be verified in order for those identities to be issued. Agents expose the SPIFFE Workload API locally to workloads, and must be installed on each node on which a workload is running.
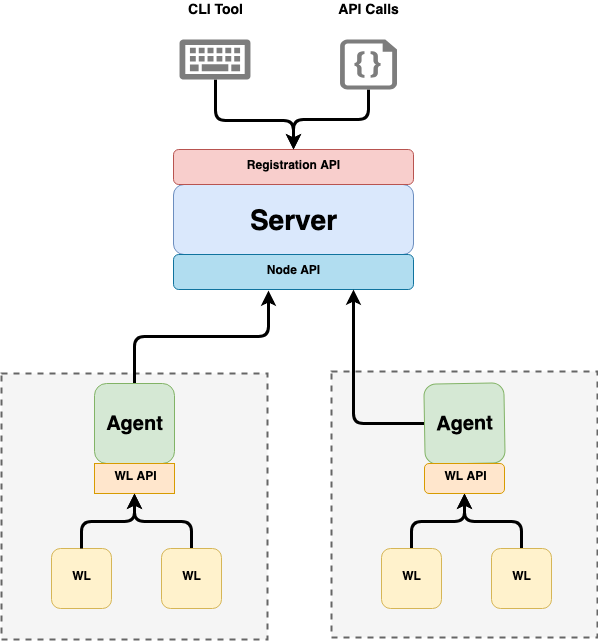
All about the Server
A SPIRE Server is responsible for managing and issuing all identities in its configured SPIFFE trust domain. It stores registration entries (which specify the selectors that determine the conditions under which a particular SPIFFE ID should be issued) and signing keys, uses node attestation to authenticate agents’ identities automatically, and creates SVIDs for workloads when requested by an authenticated agent.
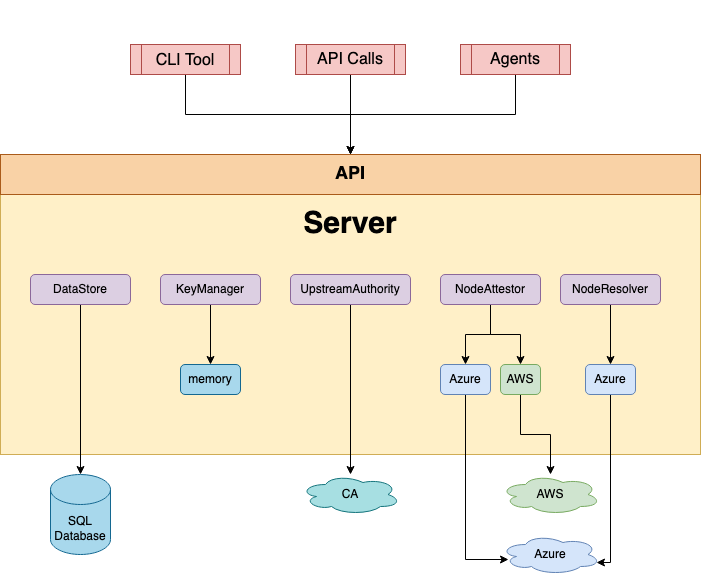
The behavior of the server is determined through a series of plugins. SPIRE comes with several plugins included, but additional plugins can be built to extend SPIRE for specific use cases. Types of plugins include:
Node attestor plugins which, together with agent node attestors, verify the identity of the node the agent is running on. See the section Node Attestation for more information.
Datastore plugins, which the server uses to store, query, and update various pieces of information, such as registration entries, which nodes have attested, what the selectors for those nodes are. There is one built-in datastore plugin which can use a MySQL, SQLite 3, or PostgresSQL database to store the necessary data. By default it uses SQLite 3.
Key manager plugins, which control how the server stores private keys used to sign X.509-SVIDs and JWT-SVIDs.
Upstream authority plugins. By default the SPIRE Server acts as its own certificate authority. However, you can use an upstream authority plugin to use a different CA from a different PKI system.
You customize the server’s behavior by configuring plugins and various other configuration variables. See the SPIRE Server Configuration Reference for details.
All About the Agent
A SPIRE Agent runs on every node on which an identified workload runs. The agent:
- requests SVIDs from the server and caches them until a workload requests its SVID
- exposes the SPIFFE Workload API to workloads on node and attests the identity of workloads that call it
- provides the identified workloads with their SVIDs
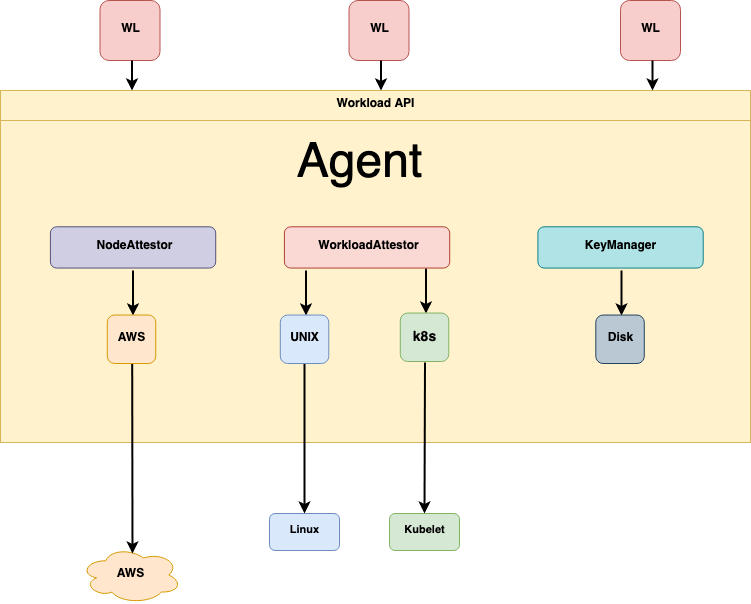
The agent’s main components include:
-
Node attestor plugins which, together with server node attestors, verify the identity of the node the agent is running on. See the section Node Attestation for more information.
-
Workload attestor plugins – which verify the identity of the workload process on the node, by querying information about the process from the node operating system and comparing it against the information you gave the server when you registered the workload’s properties using selectors. See the section Workload Attestation for more information.
-
Key manager plugins, which the agent uses to generate and use private keys for X.509-SVIDs issued to workloads.
You customize the agent’s behavior by configuring plugins and other configuration variables. See the SPIRE Agent Configuration Reference for details.
Custom Server and Agent Plugins
You can create custom server and agent plugins for particular platforms and architectures for which SPIRE doesn’t include plugins. For example, you could create server and agent node attestors for an architecture other than those summarized under Node Attestation. Or you could create a custom keymanager plugin to handle private keys in a way SPIRE doesn’t currently support. Because SPIRE loads custom plugins at runtime, you do not need recompile SPIRE in order to enable them.
A Day in the Life of an SVID
This section walks through a “day in the life” of how SPIRE issues an identity to a workload, from the time the agent starts up on a node to the point of a workload on the same node receiving a valid identity in the form of an X.509 SVID. Note that SVIDs in JWT format are handled differently. For the purposes of simple demonstration, the workload is running on AWS EC2.
- The SPIRE Server starts up.
- Unless the user has configured an UpstreamAuthority plugin, the server generates a self-signed certificate (a certificate signed with its own private key); the server will use this certificate to sign SVIDs for all the workloads in this server’s trust domain.
- If it’s the first time starting up, the server automatically generates a trust bundle, whose contents it stores in a sql datastore you specify in the datastore configuration – described in the section “Built-in plugins” in the Server plugin: DataStore sql.
- The server turns on its registration API, to allow you to register workloads.
- The SPIRE Agent starts up on the node that the workload is running on.
- The agent performs node attestation, to prove to the server the identity of the node it is running on. For example, when running on an AWS EC2 Instance it would typically perform node attestation by supplying an AWS Instance Identity Document to the server.
- The agent presents this proof of identity to the server over a TLS connection authenticated via the bootstrap bundle the agent is configured with.
- The server calls the AWS API to validate the proof.
- AWS acknowledges the document is valid.
- The server performs additional attestation steps to verify further properties about the agent node and update its registration entries accordingly. For example, if the node was attested using an AWS Instance Identity Document (IID), the attestor will perform AWS API requests to get further information for building an additional set of selectors, e.g. autoscale group or instance tag information.
- The server issues an SVID to the agent, representing the identity of the agent itself.
- The agent contacts the server (using its SVID as its TLS client certificate) to obtain the registration entries it is authorized for.
- The server authenticates the agent using the agent’s SVID. The agent, in turn, completes the mTLS handshake and authenticates the server using the bootstrap bundle.
- The server then fetches all authorized registration entries from its data store and sends them to the agent.
- The agent then sends workload CSRs to the server which the server signs and returns as workload SVIDs to the client. The client puts them in cache.
- Now fully bootstrapped, the agent starts listening on the Workload API socket.
- A workload calls the Workload API to request a SVID.
- The agent initiates the workload attestation process by calling its workload attestors, providing them with the process ID of the workload process.
- Attestors use kernel and userspace calls to discover additional bits of information about the workload.
- The attestors return the discovered information to the agent in the form of workload selectors.
- The agent determines the workload’s identity by comparing the discovered workload selectors to registration entries, and returns the correct SVID (already in its cache).
Authorized Registration Entries
The server only sends authorized registration entries to the agent. The server does the following to obtain those authorized entries:
- Query the database for any registration entries that have the agent’s SPIFFE ID listed as their “parent SPIFFE ID”.
- Query the database for what additional properties the specific agent is associated with ("node selectors").
- Query the database for any registration entries that declare at least one selection on any of those node selectors. *
- Recursively query the database for any registration entries that declare any of the entries obtained so far as their “parent SPIFFE ID” (descend to all children).
* see also mapping workloads to multiple nodes.
The server sends the resulting set of authorized registration entries to the agent.
SPIRE Concepts
This section looks at some basic concepts in SPIRE that we will refer to throughout the rest of this document.
Workload Registration
In order for SPIRE to identify a workload, you must register the workload with the SPIRE Server, via registration entries. Workload registration tells SPIRE how to identify the workload and which SPIFFE ID to give it.
A registration entry maps an identity – in the form of a SPIFFE ID – to a set of properties known as selectors that the workload must possess in order to be issued a particular identity. During workload attestation, the agent uses these selector values to verify the workload’s identity.
Workload registration is covered in detail in the SPIRE Documentation
Attestation
Attestation in the context of SPIRE, is asserting the identity of a workload. SPIRE achieves this by gathering attributes of both the workload process itself and the node that the SPIRE Agent runs on from trusted third parties and comparing them to a set of selectors defined when the workload was registered.
The trusted third parties SPIRE queries in order to perform attestation are platform-specific.
SPIRE performs attestation in two phases: first node attestation (in which the identity of the node the workload is running on is verified) and then workload attestation (in which the workload on the node is verified).
SPIRE has a flexible architecture that allows it to use many different trusted third parties for both node and workload attestation, depending on the environment the workload is running in. You tell SPIRE which trusted third parties to use via entries in agent and server configuration files and which types of information to use for attestation via the selector values you specified when you registered the workloads.
Node Attestation
SPIRE requires that each agent authenticate and verify itself when it first connects to a server; this process is called node attestation. During node attestation, the agent and server together verify the identity of the node the agent is running on. They do this via plugins known as node attestors. All node attestors interrogate a node and its environment for pieces of information that only that node would be in possession of, to prove the node’s identity.
The result of a successful node attestation is that the agent receives a unique SPIFFE ID. The agent’s SPIFFE ID then serves as the “parent” of the workloads it’s in charge of.
Examples of proof of the node’s identity include:
- an identity document delivered to the node via a cloud platform (such as an AWS Instance Identity Document)
- verifying a private key stored on a Hardware Security Module or Trusted Platform Module attached to the node
- a manual verification provided through a join token when the agent is installed
- identification credentials provisioned by a multi-node software system when it was installed on the node (such as a Kubernetes Service Account token)
- other proof of machine identity (such as a deployed server certificate)
Node attestors return an (optional) set of node selectors to the server that identify a specific machine (such as an Amazon Instance ID). The set of selectors from attestor become the set of selectors associated with the agent node’s SPIFFE ID.
The following diagram illustrates the steps in node attestation. In this illustration, the underlying platform is AWS:
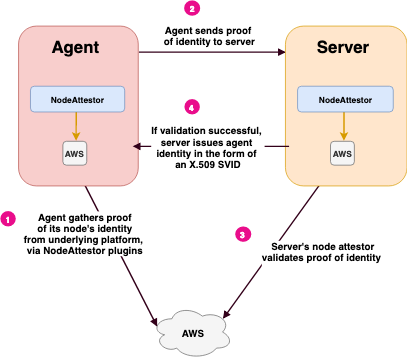
Summary of Steps: Node Attestation
-
The agent AWS node attestor plugin queries AWS for proof of the node’s identity and gives that information to the agent.
-
The agent passes this proof of identity to the server. The server passes this data to its AWS node attestor.
-
The server AWS node attestor validates proof of identity independently, or by calling out to an AWS API, using the information it obtained in step 2. The node attestor also creates a SPIFFE ID for the agent, and passes this back to the server process, along with any node selectors it discovered.
-
The server sends back an SVID for the agent node.
Node Attestors
Agents and servers interrogate the underlying platform through their respective node attestors. SPIRE supports node attestors for attesting node identity on a variety of environments, including:
- EC2 instances on AWS (using the EC2 Instance Identity Document)
- VMs on Microsoft Azure (using Azure Managed Service Identities)
- Google Compute Engine Instances on Google Cloud Platform (using GCE Instance Identity Tokens)
- Nodes that are a member of a Kubernetes cluster (using Kubernetes Service Account tokens)
For cases where there is no platform that can directly identify a node, SPIRE includes node attestors for attesting:
with server-generated join tokens – A join token is a pre-shared key between a SPIRE Server and Agent. The server can generate join tokens once installed that can be used to verify an agent when it starts. To help protect against misuse, join tokens expire immediately after use.
using an existing X.509 certificate – For information on configuring node attestors, see the SPIRE Server Configuration Reference and SPIRE Agent Configuration Reference.
Workload Attestation
Workload attestation asks the question: “Who is this process?” The agent answers that question by interrogating locally available authorities (such as the node’s OS kernel, or a local kubelet running on the same node) in order to determine the properties of the process calling the Workload API.
These properties are then compared against the information provided to the server when you registered the workload’s properties using selectors.
These types of information might include:
- How the process is scheduled by the underlying operating system. On a Unix-based systems, this might be by User ID (uid), Group ID (gid), filesystem path, etcetera.)
- How the process is scheduled by an orchestration system such as Kubernetes. In this case, the workload might be described by the Kubernetes Service Account or namespace it is running in.
While both agents and servers play a role in node attestation, only agents are involved in workload attestation.
The following diagram illustrates the steps in workload attestation:
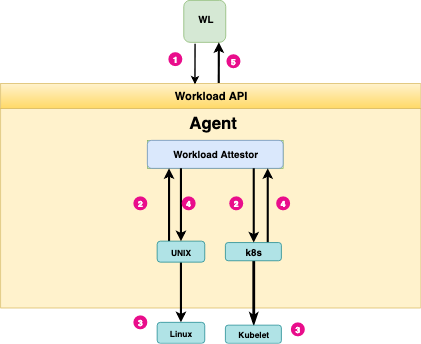
Summary of Steps: Workload Attestation
- A workload (WL) calls the Workload API to request an SVID. On Unix systems this is exposed as a Unix Domain Socket.
- The agent interrogates the node’s kernel to identify the process ID of the caller. It then invokes any configured workload attestor plugins, providing them with the process ID of the workload.
- Workload attestors use the process ID to discover additional information about the workload, querying neighboring platform-specific components – such as a Kubernetes kubelet as necessary. Typically these components also reside on the same node as the agent.
- The attestors return the discovered information to agent in the form of selectors.
- The agent determines the workload’s identity by comparing discovered selectors to registration entries, and returns the correct cached SVID to the workload.
Workload Attestors
SPIRE includes workload attestor plugins for Unix, Kubernetes, and Docker. For details on specific attestors supported by default, see the section Attestation.
